Node Hierarchies
Data Flow #
Nodes are connected in a parent / child hierarchy. This is first and foremost a transform hierarchy: parent transformations are applied to the child, composited with the child’s own transformation - so the parent moves the child with itself. The parent child relationship is used to flow other data along the hierarchy, such as image data between a chain of video nodes. It’s also used to represent collection relationships / modifier relationships: for example a Particle Root node represents a collection of particles, and emitters and affectors that work on the collection are linked as children of the Particle Root node; or in another example, a 3D Object node is the parent and there are Deformer nodes attached as children that modify the parent 3D Object’s mesh. Similarly, a Post FX node parented to a Video Processing node modifies the image that is contained in the Video Processing node.
The Root node is the entry point for the scene. Everything that is rendered in the scene must be connected via the root node, directly or via a parent hierarchy. Post FX that are attached to the root node or camera nodes effect the rendered scene.
Nodes can also be connected across the branches of the transform hierarchy via input connectors. This is used to pass the data owned by one node into another’s processing; for example, a 3D Object node may be connected to an input of a Particle Mesh Emitter node in order to define the mesh used for emission.
Inputs are weakly typed: when a node is connected as an input to another node, the relevant information from the connected node is automatically chosen, if applicable. There are hints when connecting inputs about which nodes make for valid connections, and invalid ones may be rejected if a connection is attempted. Some inputs take only one node at a time and some take multiple nodes. Input connectors are also created for all numeric properties on a node, allowing them to be driven by other nodes - e.g. modifiers.
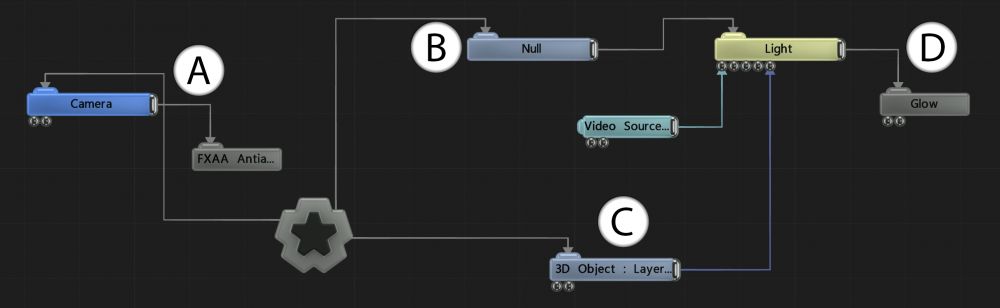
| Item | Description |
|---|---|
| A | The FXAA node (as with other Post-FX nodes) is parented to the Camera node, and will only be applied when the scene is viewed through that Camera. |
| B | This Null node is the parent of the Light. Transforming the Null will also transform the Light. |
| C | This 3D Object is connected to the Target Node input of the Light Node, meaning that the 3D Object’s position will be used as the target for the rotation of the light. The Video Source node is connected to the Projection Image of the Light, causing the image stored in the Video Source to be used as the light’s projection / gobo image. |
| D | This Glow node is connected to the Light node, however light nodes do not contain images so this does not form a valid parent/modification relationship. As such, the glow is considered to be connected to the Root via the hierarchy and is applied to the whole scene. This does mean that if the Light is disconnected from its parent, the Glow no longer has a connected path through the hierarchy to the Root node, so the glow will also no longer be applied to the scene. |
Order Of Operations #
For nodes sharing the same parent, the order of operations for processing the nodes is decided based on the Y position of the node in the nodegraph, or the X position if the Y values are the same. Nodes with larger X or Y values are calculated first, meaning that if Effect A needs to be run after Effect B, Effect A should be placed lower in the nodegraph than Effect B.
| Order A | Order B |
|---|---|

|
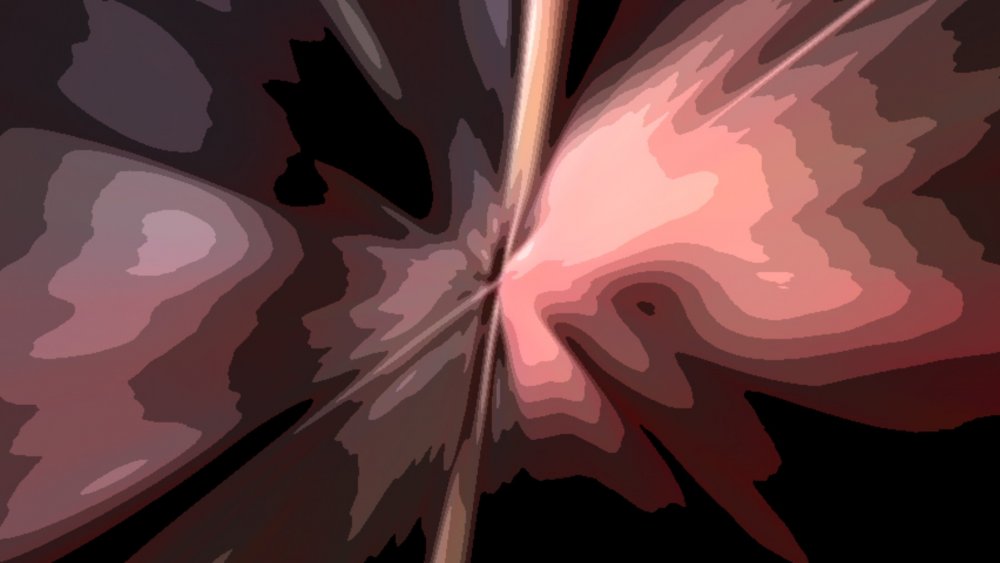
|
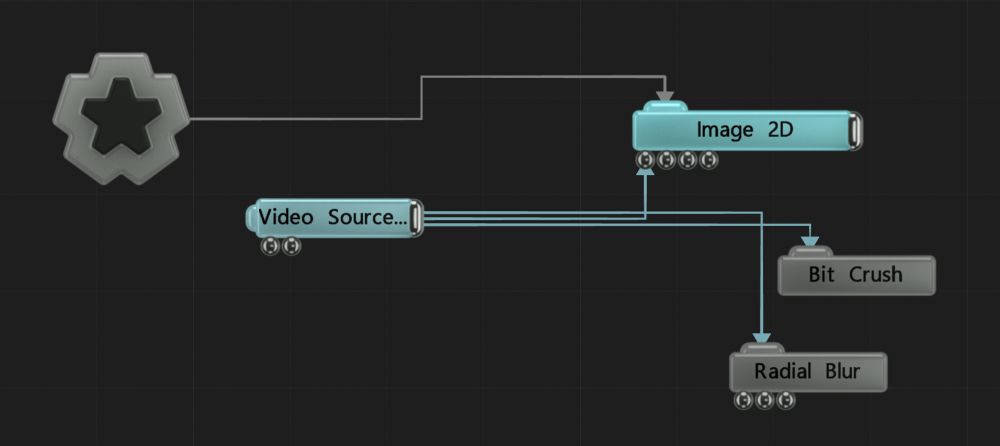
|
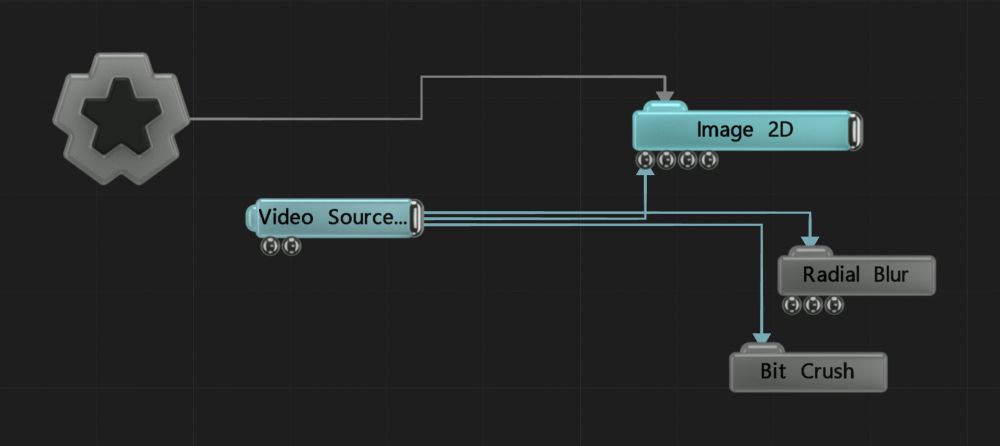
|
The images on the left shows the radial blur being done after the bit crush, with the reverse being shown on the image on the right. This is decided by the position of both the radial blur and the bit crush in the nodegraph.

